

CacheLib 解决的问题
| 挑战 | 方案 |
|---|---|
| 需要大容量缓存系统 | DRAM 与 flash 混合式存储 |
| 存储对象规模差异大 | 根据对象规模采取不同策略 |
| 不加特殊控制,容易 OOM | 动态监控并管理系统资源 |
| 无法高效缓存空结果 | 提供 negative caching 支持 |
| 更新结构化对象字段较麻烦 | 支持直接更新结构化对象字段 |
| 服务重启影响缓存性能 | 支持热重启 |
CacheLib 基本概念
Item 与 Handle
Item 是表示缓存对象的逻辑单元,占据一定的内存空间。为了防止 Item 被访问时失效(被删除、逐出等),CacheLib 禁止直接访问 Item,而是要求通过 Handle 对 Item 进行访问,且对 Item 进行引用计数。只有一个 Item 被引用的次数为 0 时,它才有可能被删除或逐出。
每个 Item 存储时,均需附加 32 字节的元信息。
Slab 是缓存分配的物理单元,大小为 4MB。因此,每个 Item 所需空间不得超过 4MB。Item 可以串联起来,用来存储更大的对象。
代码:allocator/Handle.h
MemoryPool
CacheLib 允许将 Cache 划分为不超过 64 个 MemoryPool。每个 MemoryPool 可以根据应用场景,分别存放不同种类的对象。因为缓存对象的替换只会发生在 MemoryPool 内部,MemoryPool 之间则是相互隔离的,所以可以起到提升命中率的作用。
此外,相比于用一整块 Cache 存储各类对象,让每个 MemoryPool 内部存放大小相近的对象,在提高空间利用率、减少内存碎片方面也有好处。
HybridCache
HybridCache 将缓存从 DRAM 存储扩展到 NVM 存储。由于 NVM 存储设备价格一般比 DRAM 低,且通常能提供更大规模的存储,通过 HybridCache,系统可以在扩大缓存空间的同时,控制甚至降低设备成本。
尽管 HybridCache 将缓存分为两个层级,但只有处于 DRAM 中的 Item 才允许由外界直接访问。按照 CacheLib 的设计,NVM 的存储细节应当对用户透明。MemoryPool 等设计也只在 DRAM 存储层级内适用。
这一设计思想很像操作系统中 memory swapping 的设计。
Navy
Navy 是一个缓存引擎,为 HybridCache 服务,旨在基于 SSD 的物理特性做针对性的优化。SSD 最大的特点在于块式存储,且擦除次数有限,因此 Navy 应避免频繁写入,且需要做好磨损均衡。
为此,Navy 需要对小 Item 与大 Item 采用不同的存储策略。Navy 内部分为两个引擎:Small Item Engine 与 Large Item Engine,并根据 Item 的大小选择合适的引擎分别处理。
一个 SSD 页面的大小为 4KB,而区分大小 Item 的界限为 2KB。对于小 Item 的缓存(SOC),一个页面中可以存放多个 Item。CacheLib 会根据 Item key 的哈希选择具体的页面,而在页面内采用 FIFO 的替换策略。此外,对于每个页面,CacheLib 会在 DRAM 内维护一个快速查询器(BloomFilter),用于在缓存缺失时避免不必要的文件读取,提高查询效率。对于大 Item 的缓存(LOC),CacheLib 会在 DRAM 中为每个 Item 维护一个索引。
此外,为提升 Navy 引擎的并发性,所有的请求都应是异步的。这就要求 Navy 内部实现一个异步调度器。
示例代码学习:Set up a simple dram cache
类型梳理
一共有四种
CacheTrait,每个CacheTrait由MMType、AccessType、AccessTypeLocks三个要素构成。Cache = CacheAllocator<CacheTrait>Cache::Config = CacheAllocatorConfig<Cache>- 可以从
Cache::Config构造出Cache
- 可以从
Cache::Item = CacheItem<CacheTrait>Cache::Key = Cache::Item::KeyKey实际上是folly::StringPiece的派生类,但重载了比较函数,目的是在短 key 的比较上取得优势
Cache::NvmCache = NvmCache<Cache>Cache::NvmCacheConfig = NvmCache::Config- 可以从
Cache和NvmCacheConfig构造出NvmCache
- 可以从
NvmCache::Item = Cache::Item我认为 CacheLib 如此依赖模板来实现静态多态的目的是,尽可能提升运行时效率。
接口梳理
ReadHandle find(Key key):读 CacheWriteHandle allocate(PoolId poolId, Key key, u32 size, u32 ttlSecs = 0):分配一块缓存;分配得到的WriteHandle不会立刻生效,需要配合insert或insertOrReplace接口才能写入 Cachebool insert(const WriteHandle &handle):将WriteHandle写入 Cache;若 key 已存在,则拒绝写入,并返回失败WriteHandle insertOrReplace(const WriteHandle &handle):将WriteHandle写入 Cache;若替换了某个已有Item,则将其以WriteHandle的形式返回WriteHandle findToWrite(Key key):查找指定 key 的Item,并返回可用于更新的WriteHandle
实现细节
对于每一个接口,都有非常多的情形和边界条件需要考虑。这里仅仅列出各接口的大致执行流程。
find()
find() 接口首先会调用 findFastInternal() 接口,在 DRAM 内快速查询目标 key。实施查询时,会采用该缓存实例的 CacheTrait 中定义的 AccessType 进行查询。(CacheLib 内置的四种 CacheTrait 的 AccessType 均为 ChainedHashTable。)
如果未能在 DRAM 中找到目标 key,且 HybridCache 可用,则调用 NvmCache 的 find 接口进一步查询。需要注意的是,由于 NVM 查询的异步性,这种情况下返回的 Handle 是一个 Future。
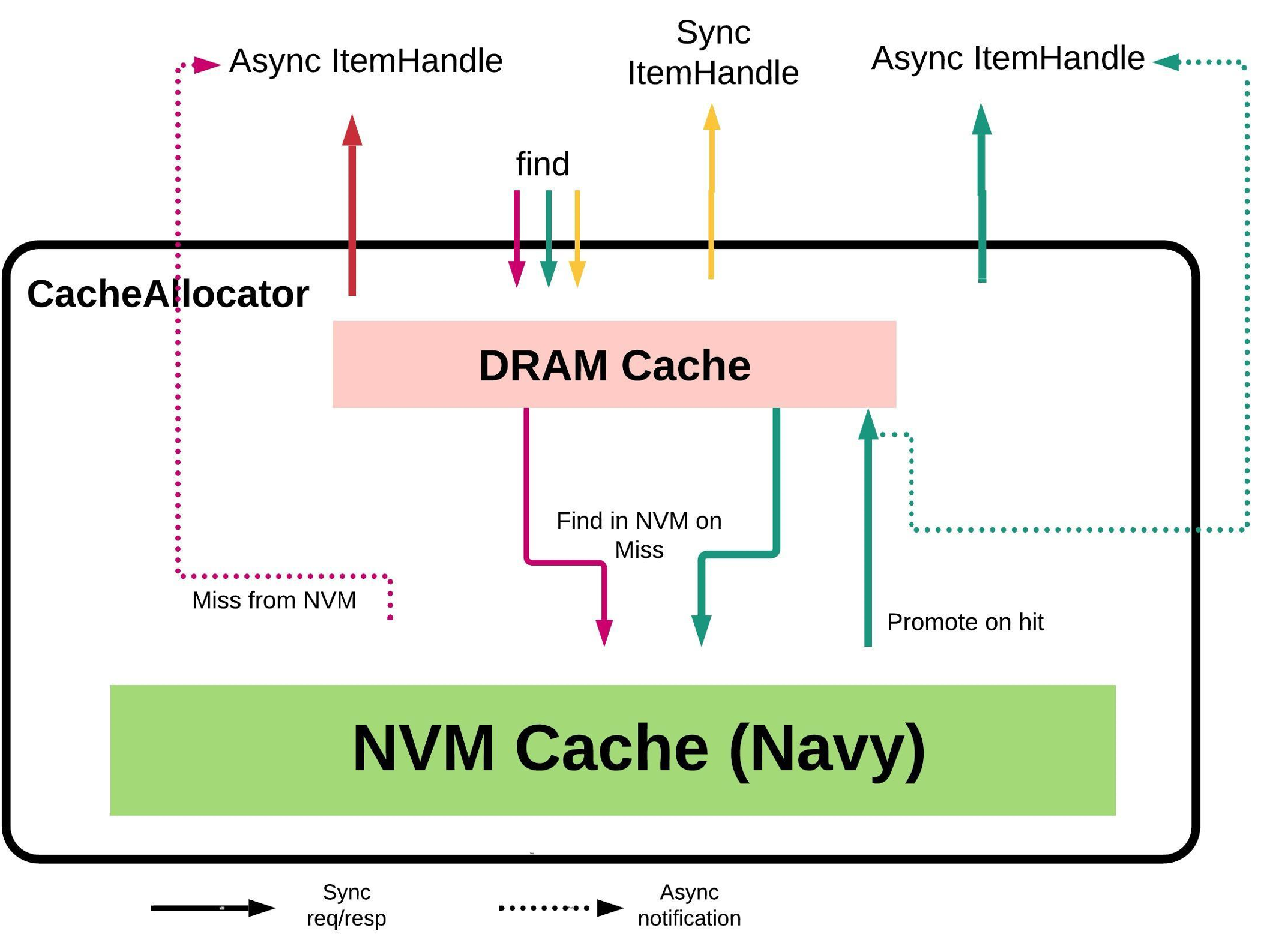
allocate()
CacheLib 会根据 Item 的大小,将 Item 划入相应的 AllocationClass。
allocate() 接口首先会尝试在 MemoryPool 内寻找空闲内存。若内存已满,则会尝试调用 findEviction() 接口,逐出某个现有 Item。
如果成功分配了空闲内存,CacheLib 就会用这块内存封装出一个 WriteHandle,供上层使用。
若启用 HybridCache,分配操作的流程如下图所示。
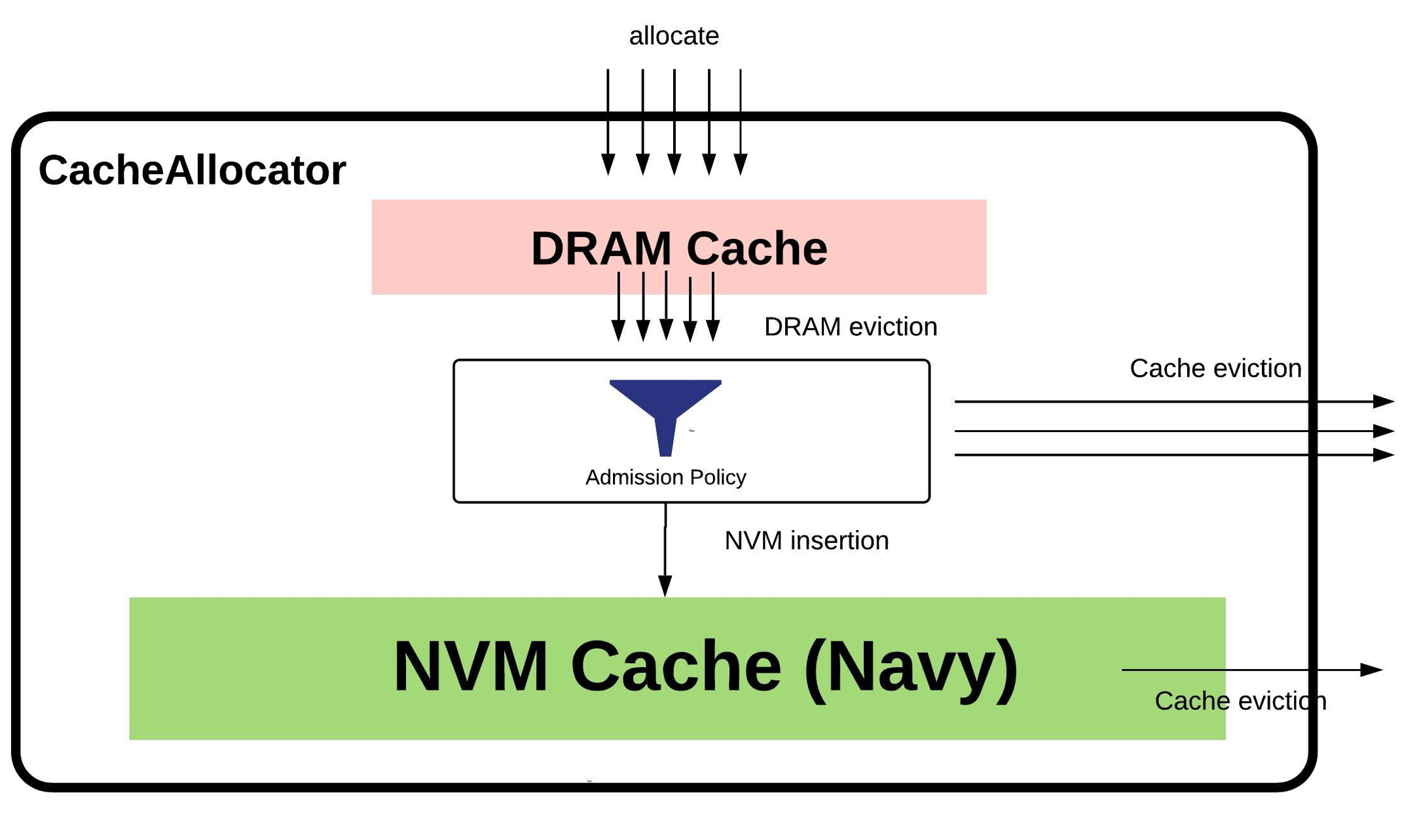
insertOrReplace()
由于 HybridCache 场景下,
insert()接口不可用,所以这里只分析insertOrReplace()接口的实现。注意,由于内存不足而发生的逐出发生在
allocate()接口中。这里的 replace 指的是插入同 keyItem时的替换。
CacheLib 的插入过程有两步要做:
更新内存管理(memory management)信息(例如,如果采用 LRU 策略管理缓存,那就需要更新对应的
LruList,见allocator/MMLru.h相关代码)将
Item写入缓存(实际的插入操作)
在将 Item 写入缓存时,如果有某个同 key Item 被替换出来,那也需要在内存管理信息中将这个被替换出来的 Item 记录去掉。
如果被替换出来的 Item 在 NVM 中也有一份副本,那么需要将它在 NVM 中的那份副本也删掉。
findToWrite()
findToWrite() 接口的实现与 find() 的基本一样,缺省表现是会额外调用一次 invalidateNvm() 接口,使其在 NVM 中失效。
Kangaroo
核心目标
Kangaroo 的核心目标是,对于在 flash 上缓存海量小 Item 的场景,针对 flash 设备的物理特性,对缓存系统进行优化,从而在 DRAM 使用量和 flash 写次数之间达成平衡。
Kangaroo 的思路是,将 log-structured 和 set-associative 缓存设计结合使用,取长补短。前者的优势在于降低 flash 的写次数,后者的优势在于降低 DRAM 的使用量。
Kangaroo 构造了一个三级缓存架构:DRAM Cache(全部在内存中,容量<1%)、KLog(数据在 Flash 中,索引在内存中,容量≈5%)、KSet(数据在 Flash 中,容量≈95%)。查询和插入操作的流程如下图所示。
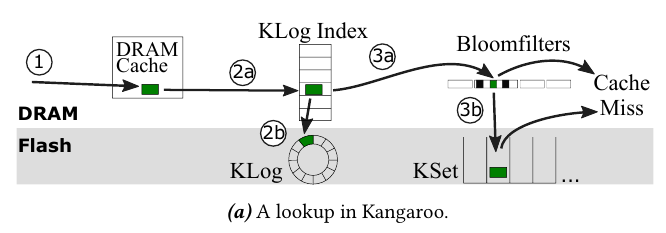
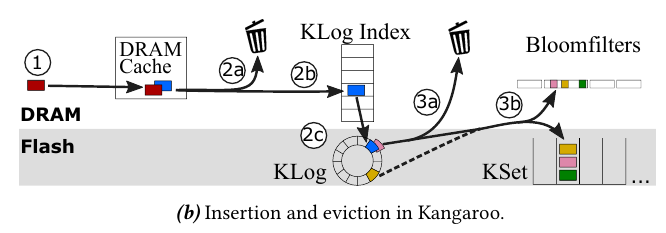
为了降低 flash 的写次数,Kangaroo 还使用了以下技巧:
批量写入——从 KLog 逐出一项数据到 KSet 时,会顺带将 KLog 中所有属于同一组的数据一并搬到 KSet 中
选择性接纳——为 KSet 一次接纳的数据量设定下限,若 KLog 一次无法提供足够多的数据,则 KSet 会拒绝这次写入
RRIParoo——将 RRIP 策略应用于 KSet 的设计中,从而提升缓存命中率
尚未在 CacheLib 主分支中找到 Kangaroo 相关代码。
内存分配
基本设计
内存管理的代码主要位于 allocator/memory 目录下。
每个 MemoryPool 内部独立管理内存,每个 MemoryPool 可指定一组 AllocationClass。
进行内存分配时,首先在 MemoryPool 的 AllocationClass 当中找到一个刚好能分配目标空间的一级。这里,CacheLib 保证维护的 AllocationClass 规模列表是有序的,从而可以二分查找。找到合适的 AllocationClass 后,即可进行内存分配。
Slab 是内存管理的基本单元。一个 Slab 内可以有多个 allocations。AllocationClass 的最小规模为 64B,最大规模为 4MB。
Slab 管理与回收——AllocationClass 视角
AllocationClass 内维护了以下成员:
freeSlabs_,空Slab列表。AllocationClass本身无法构造Slab,因此这些空Slab是由上层的MemoryPool添加的。allocatedSlabs_,已分配的Slab列表。一个Slab被分配后,它的地址就会写入allocatedSlabs_中。当出于 rebalance 或 resize 的原因,需要从AllocationClass释放空间时,allocatedSlabs_中的Slab可能被删除。freedAllocations_,已回收的 allocations 列表。一个 allocation 被回收后,就会记录在freedAllocations_中。下次分配 allocation 时,会首先尝试回收利用freedAllocations_中的 allocation。currSlab_,当前活跃的Slab。Slab是切成一份一份 allocations 之后提供给上层的。在分配 allocation 的过程中,一个Slab可能还没消耗完。这时,这个Slab就处于活跃状态,下次分配 allocation 时也将从该活跃的Slab下手。currOffset_,当前活跃Slab已切分的偏移量。下次分配 allocation 时,就从当前活跃Slab的currOffset_偏移处开始分配。slabReleaseAllocMap_,维护将被释放的Slab内仍存留的有效 allocations 的下标,用于辅助Slab释放的过程。原则上,只有当一个Slab内不存在有效 allocation 时,这个Slab才能真正意义上被删除。因此,这是一个“异步”的过程,需要引入一些成员变量来维护。
一个典型的生命周期如下所示:
系统启动时,
AllocationClass内尚无可用空间,MemoryPool将一个Slab添加到该AllocationClass的freeSlabs_中。AllocationClass从freeSlabs_中取出一个Slab,添加到allocatedSlabs_中,并将其标记为currSlab_。AllocationClass从currSlab_中切出一段 allocation,用于给上层系统分配Item,同时更新currOffset_。上层系统删除
Item时,AllocationClass也将对应的 allocation 回收,放入freedAllocations_中,以供未来复用。上层系统对
MemoryPool进行 rebalance 或 resize 时,AllocationClass会从freeSlabs_和allocatedSlabs_中删掉一些Slab。如果Slab中仍存在有效的 allocation,AllocationClass会告知上层系统。
多级 freeSlabs_ 设计
SlabAllocator、MemoryPool 和 AllocationClass 均有 freeSlabs_ 这一成员,用于维护当前可分配的空闲 Slab 列表。每一级只能支配属于自己的 freeSlabs_,具体而言:
AllocationClass只能支配AllocationClass内部的空闲Slab。如果当前freeSlabs_为空,该AllocationClass将无法分配新的Slab。MemoryPool可以从自己的freeSlabs_中拿出一些空闲Slab,加入其下属AllocationClass的freeSlabs_中,也可以利用自己的freeSlabs_列表在AllocationClass之间进行重平衡操作。SlabAllocator直接管理系统内的所有Slab,也可以从自己的freeSlabs_中取出一些Slab加入某个MemoryPool的freeSlabs_中。此外,SlabAllocator还可以通过自己的freeSlabs_在MemoryPool之间重新分配空间。
我认为这一设计有如下优势:
每一级有自己的空闲
Slab列表,能够较为灵活地调整内部空间分配。当上级存储要求下级存储释放一些空间时,如果下级存储的
freeSlabs_中有空闲Slab,可直接释放。
动态调整流程分析
CacheLib 会定时对 MemoryPool 中的 AllocationClass 进行重平衡的操作。用户也可能手动调整 MemoryPool 的大小。这些动态调整内存分配的行为均有可能触发 SlabRelease 操作。
SlabRelease 会直接要求某个 AllocationClass 让出一个 Slab,具体的情形如下:
若
freeSlabs_中就有空闲Slab,则直接提供。否则,在
allocatedSlabs_中随机选择一个Slab,准备将其释放。原则上,只有当一个Slab内不存在有效 allocation 时,这个Slab才能被释放。因此,需要执行以下流程(代码实现见AllocationClass::pruneFreeAllocs()和CacheAllocator::releaseSlabImpl()):- 根据该
AllocationClass的freedAllocations_列表,标记出该Slab内还存有哪些activeAllocations; - 对于这些
activeAllocations,首先尝试在MemoryPool内部重新分配空间,将这些旧的 allocations 重新写入缓存; - 如果不成功,则将其逐出缓存。
- 根据该
由于 b. 的存在,这一流程对缓存中的内存碎片进行了整理,提升了内存空间的利用率。
侵入式 SList 与高效的 CompressedPtr
这是我第一次知道侵入式链表的概念,颠覆了我对链表的传统观念。
AllocationClass 内使用一个侵入式链表来维护已回收的 allocations。采用侵入式链表可以直接在待回收的内存上原地存储下一节点的地址,能够节省空间并提高效率,是非常巧妙的设计。
用于表示 allocation 的地址也不采用原始指针,而是重新定义了一个 CompressedPtr,采用一个 32 位整数表示 Slab 编号和 allocation 编号两部分信息。这里做一个简单的计算:一个 Slab 内最多分配 Slab 编号。一个 Slab 的大小为 4MB,这样就能表示
Slab 与 SlabHeader
每个 Slab 需要维护自身的 poolId、classId 等元信息,这些元信息用一个 SlabHeader 结构存储。CacheLib 的策略是,将整块内存分为两部分,前面一小部分依次存放各个 SlabHeader,剩余部分用于分配 Slab。
这就要求 SlabAllocator 在构造时就估计好这个切分的界限。由于 Slab 与 SlabHeader 的大小都是已知的(分别为 4MB 和 7B),只要知道内存总量,这一估计并不困难,具体实现见 SlabAllocator::computeSlabMemoryStart()。
SlabHeader 结构在定义时注明了 __attribute__((__packed__)),从而能更紧凑地利用内存空间。
链式存储
总体设计
每个 Item 所占空间不得超过一个 Slab 的大小(4MB)。为了支持更大对象的存储,CacheLib 引入链式存储机制,通过串联多个 Item 的方式实现这一需求。
CacheLib 的设计是,让一个普通的 CacheItem 充当祖先节点,另外一些 CacheChainedItem 串成一个单链表,“接在”这个祖先节点之后。每个 CacheChainedItem 均需存储祖先节点的地址,以便知道自己祖先是谁,也要存储后继节点的地址,以实现链表的功能。整个缓存系统内还要维护一张大表(使用 CacheTrait::AccessType 指定的容器实现),用于根据祖先节点查找链表的起点。
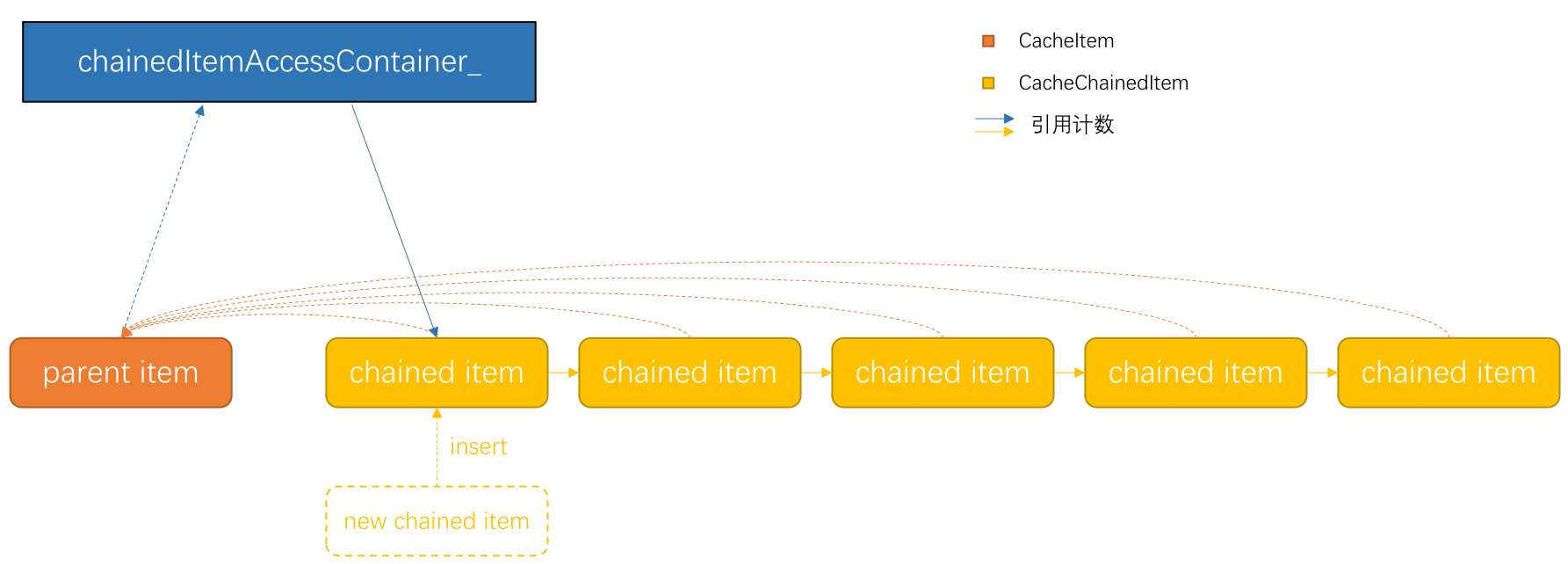
CacheChainedItem 内存布局
1 | | --------------------- | |
CacheChainedItem 与 CacheItem 在内存布局上大体相同,都有五个元信息字段,都使用 KAllocation 维护对象数据。
在这里简单补充一下
KAllocation的结构和优化细节。
KAllocation需要维护两部分内容:Item的 key 与Item的 payload。两者均为可变长数据,且连续地存储在data_字段内,这就需要KAllocation额外维护两者的数据长度。
KAllocation巧妙地使用一个 32 位整数字段维护两个长度:用前 8 位表示 key 的长度,后 24 位表示 payload 的长度,以达到压缩空间的目的。
和普通的 CacheItem 不同之处在于:
CacheChainedItem将祖先节点的指针作为 key,从而可以根据祖先节点的地址找到CacheChainedItem;CacheChainedItem需要利用 payload 的前几个字节存储后继节点的指针,以实现链表的功能。
以上两个指针均用 CompressedPtr 实现,用于减小空间开销。
引用计数
CacheItem 内有一个字段 ref_,用来维护该 CacheItem 的引用计数等信息,用一个 32 位整数表示。这里也用到了压位技巧,此处不展开。
以下两种情形会计入引用:
通过
ReadHandle或WriteHandle被用户使用;作为
CacheChainedItem被父节点引用。
这张表格描述了引用计数更新的规律:
| 场景 | 提供给用户使用 | 父节点引用 |
|---|---|---|
| 计数增加 | Handle 构造时 |
Item 进入链表时 |
| 计数减少 | Handle 析构时 |
Item 离开链表时 |
Handle 做到的与没做到的
根据 CacheLib 代码注释的描述(见 allocator/CacheItem.h),Handle 的作用是保证引用计数的正确性,类似 std::shared_ptr。可仔细阅读代码后,我发现 Handle 并不如智能指针那样“智能”。首先,当 Item 进入和离开链表时,Item 的引用计数还是要由上层的 CacheAllocator 手动更新。其次,Handle 也不会在构造时自动将 Item 的引用计数加一,还是需要交由上层接口自行控制。
参见
CacheAllocator::acquire(),CacheAllocator的其他接口如果想要从Item构造Handle,应当通过这一方法:
2
3
4
5
6
7
8
9
10
11
12
typename CacheAllocator<CacheTrait>::WriteHandle
CacheAllocator<CacheTrait>::acquire(Item* it) {
if (UNLIKELY(!it)) {
return WriteHandle{};
}
SCOPE_FAIL { stats_.numRefcountOverflow.inc(); };
incRef(*it);
return WriteHandle{it, *this};
}
当然,Handle 还是做到了一些事情的。比如,Handle 确实会在析构时将 Item 的引用计数减一。另外,Handle 禁用了拷贝构造和拷贝赋值,避免拷贝造成引用计数的管理混乱。对 CacheLib 内部实现而言,Handle 也许并不够“智能”。但对用户而言,Handle 确实做到了用户透明的引用计数控制。
结构化存储——以 Map 为例
概述
Map 基于链式存储实现。CacheLib 用一个祖先节点存储映射关系(采用哈希表),用剩余的后继节点存储映射值,映射关系里只存储映射值的地址。整个 Map 构成一个大的 CacheLib 存储对象。
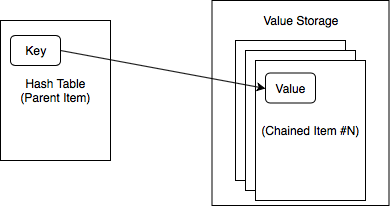
CacheLib 引入了一个 BufferManager,用于管理 Value Storage 部分可分配的空间。需要注意的是,BufferManager 并不拥有内存,也不占据存储空间,而更像是一个工具类,辅助 Map 进行内存空间的使用。
Map 有两个重要字段:hashtable_ 与 bufferManager_。接下来两节将分别介绍这两个字段的实现细节。
映射关系
hashtable_ 用于维护这个 Map 的映射关系,它存储于祖先节点的内存空间中。hashtable_ 的类型为 TypedHandle<HashTable>,这意味着它与一般的 Handle 本质相同,只是内存被解释为 HashTable 类型,方便编程。
HashTable 采用了一个开放地址的实现方式,只用一段连续的地址空间即可完成。HashTable 的主体数据部分为一个 Entry[],每个 Entry 表示一个键值映射,定义如下:
1 | template <typename Key> |
Key 可以是自定义类型,前提是长度固定,且不能引用堆上数据(意味着不能用 std::string)。
BufferAddr 用来描述值在 Value Storage 中的地址,同样采用了压位的技巧,前 22 位用于表示在 Buffer 内的位置(0~4MB),后 10 位用于表示在第几块 Buffer 内。
当 Handle 存储空间用满时,HashTable 会尝试在 MemoryPool 内重新申请一个空间,并将现有的映射关系重哈希、迁移过去。
其余部分实现与传统的 HashTable 差不多,此处不再展开。
BufferManager
BufferManager 内保存了指向 CacheAllocator 实例以及祖先节点的指针,此外还有一个 std::vector<Item*> buffers_,依次存放每块 Buffer 所对应的 Item 的指针。
当 Map 需要添加一组新的键值对时,BufferManager 首先会遍历每一块 Buffer,询问是否有足够的空间。若有,则写入对应的值,并更新映射关系。若没有,Map 会让 BufferManager 申请一块新的 CacheChainedItem 后,重新给出一个可分配的地址,写入待添加的值,并由 Map 更新映射关系。
由于每次需要分配的空间长度并不固定,Buffer 内采用了较为简单的分配策略:直接在上一次分配的地址之后分配下一个地址。即使因删除而存在空洞,也不会直接复用,而只有在必要的情况下才会重新整理压缩 Buffer 内分配的空间。
Navy 异步调度器
设计层次
Navy 引擎中,数据主要存放于 SSD 上,因此数据的读写是一个异步的过程。为此,Navy 需要实现一个异步调度器。
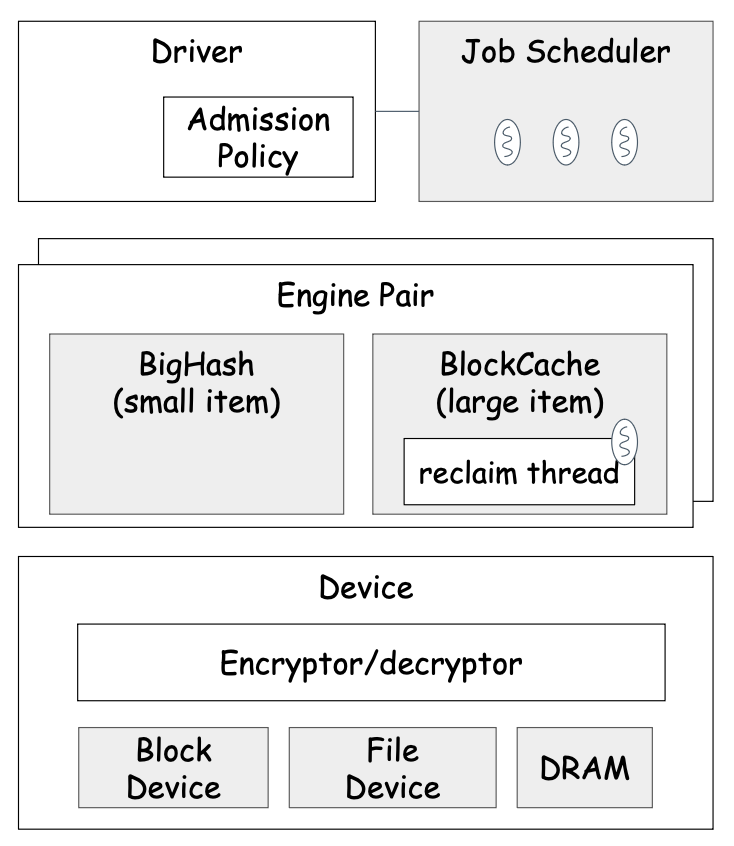
Navy 引入了一个 Driver 层,向上提供一系列异步接口,向下对接存储部件,并负责控制异步调度器。
在异步调度器的部分,Navy 定义了一个抽象类 JobScheduler,系统中默认使用的是派生类 OrderedThreadPoolJobScheduler,实现细节之后分析。
在 Driver 层之下,就是具体的存储引擎。由于 Driver 层已经处理好异步调度,存储引擎的代码都是在线程池中执行的,因此只需按同步的方式实现存储引擎接口即可。
一例看懂
Driver、JobScheduler与Engine的关系(注意代码中的注释):
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
Status Driver::lookupAsync(HashedKey hk, LookupCallback cb) {
lookupCount_.inc();
XDCHECK(cb);
// Driver 将异步任务传给 JobScheduler
scheduler_->enqueueWithKey(
[this, cb = std::move(cb), hk, skipLargeItemCache = false]() mutable {
// 该函数将在新线程上执行
Buffer value;
Status status{Status::NotFound};
if (!skipLargeItemCache) {
// largeItemCache_ 是一个 Engine 实例
// Driver 驱动下层引擎执行 IO 任务
status = largeItemCache_->lookup(hk, value);
if (status == Status::Retry) {
return JobExitCode::Reschedule;
}
skipLargeItemCache = true;
}
if (status == Status::NotFound) {
// smallItemCache_ 是另一个 Engine 实例
// Driver 驱动下层引擎执行 IO 任务
status = smallItemCache_->lookup(hk, value);
if (status == Status::Retry) {
return JobExitCode::Reschedule;
}
}
if (cb) {
// 通过回调函数通知异步任务完成
cb(status, hk, std::move(value));
}
updateLookupStats(status);
return JobExitCode::Done;
},
"lookup",
JobType::Read,
hk.keyHash());
return Status::Ok;
}
JobScheduler
JobScheduler 是异步调度器的抽象类,任何一个具体的异步调度器,都需要实现 JobScheduler 定义的五个抽象方法:
1 | class JobScheduler { |
其中,最关键的接口是 enqueueWithKey 与 enqueue,它们将 job 加入调度队列中,交给对应的线程池执行。
Navy 实现了两个派生类:ThreadPoolJobScheduler 与 OrderedThreadPoolJobScheduler。下面分别介绍这两个派生类。
如果只想知道
JobScheduler的总体设计,而不关心具体实现细节,建议去看官方教程。那里对两个不同的派生类做了模糊处理(压根就没提),虽然有些事实性错误,但更容易理解一些。
ThreadPoolJobScheduler
ThreadPoolJobScheduler 为读和写任务分别创建了一个线程池(ThreadPoolExecutor)。每当有新任务加入时,ThreadPoolJobScheduler 就会根据任务的类别,将其移动到对应的线程池中。
默认设置下,每个线程池有 32 个线程。每个线程都有对应的 JobQueue 实例,用于维护自己需要处理的任务队列。
线程池拿到任务后,就会选择一个线程,将任务加入它的 JobQueue 实例中,交给该线程执行。
这里补充交代一些细节:
线程池选择线程的依据是,如果是用
enqueueWithKey接口添加的任务,那就根据key的模选择,否则就轮流;部分类型的任务(
JobType::Reclaim和JobType::Flush)可以“插队”,从而优先被线程执行;为保证线程安全,在需要变更任务列表时,
JobQueue会用互斥锁进行保护;为避免线程空转,
JobQueue引入一个std::condition_variable,在任务执行完毕时陷入阻塞状态,等到下一个任务被加入时重新唤醒。
OrderedThreadPoolJobScheduler
OrderedThreadPoolJobScheduler 在满足 ThreadPoolJobScheduler 的一切特性的同时,保证了 key 相同的任务执行时的有序性。
它的核心想法是,引入一个“缓冲带”,在接受一个新任务之前,检查是否有同样 key 的任务正在执行或等待执行中。如有,将其追加到该 key 的缓冲队列中。否则,直接交给线程池去执行。
为了高效实现这一机制,OrderedThreadPoolJobScheduler 引入大量桶(默认值为 key 的模选择对应的桶。
兼容新的存储介质
Navy 引入 Driver 层的这一设计,让我们能够进行扩展以兼容新的存储介质。
还是以 Driver::lookupAsync 这一接口为例,注意它加入调度器的具体任务:
1 | Status Driver::lookupAsync(HashedKey hk, LookupCallback cb) { |
它大体上进行了这样的流程:先查找 largeItemCache_,如果未命中再查找 smallItemCache_,如果仍未命中则报告未找到。
假如我们希望引入新的存储介质,如 S3,那么只需自行实现该介质的相应接口,并在 Driver 层相应的执行流程中调用即可(例如,若 SSD 缓存中无法命中,则前往 S3 缓存进一步查找)。
本文链接:https://www.unidy.cn/articles/cachelib/